1 Basic concepts#
An LLM goes through two main phases(Lifecycle of an LLM): Training and Inference:
- Pre-training : it learns to predict the next word or token from large amounts of unlabeled text.
- Fine-tuning : The model is adapted to specific tasks or domains using labeled datasets.
- Post-training(Alignment) : it learns useful behaviors such as following instructions, tool use, and reasoning.
- Inference : The trained model responds to user inputs in real time without updating its internal parameters.
Foundational Techniques that Underpin LLM Architecture :
| Concept |
Description |
Problem Solved |
| Tokenization |
Breaks text into tokens such as subwords, characters, or word pieces |
Converts natural language into discrete units understandable by models |
| Vocabulary |
A predefined set of tokens |
Reduces Out-Of-Vocabulary (OOV) issues and standardizes encoding |
1.1 Vector Representation (Embedding Space)#
| Component |
Description |
Problem Solved |
| Token Embedding Lookup |
Each token is mapped to a high-dimensional vector (e.g., 768 or 1536 dimensions) |
Captures basic semantic relationships between tokens |
| Sentence/Paragraph Pooling |
Techniques like Mean Pooling, Attention Pooling |
Aggregates token-level vectors into sentence-level representation |
Multilingual Embedding Alignment is a capability that must be actively built during the training process through the use of specific data, model architectures, and objective functions—it is not something the model acquires naturally on its own. Its implementation relies on training strategies such as shared tokenizers, multilingual corpora, contrastive learning, and parallel sentence alignment mechanisms.
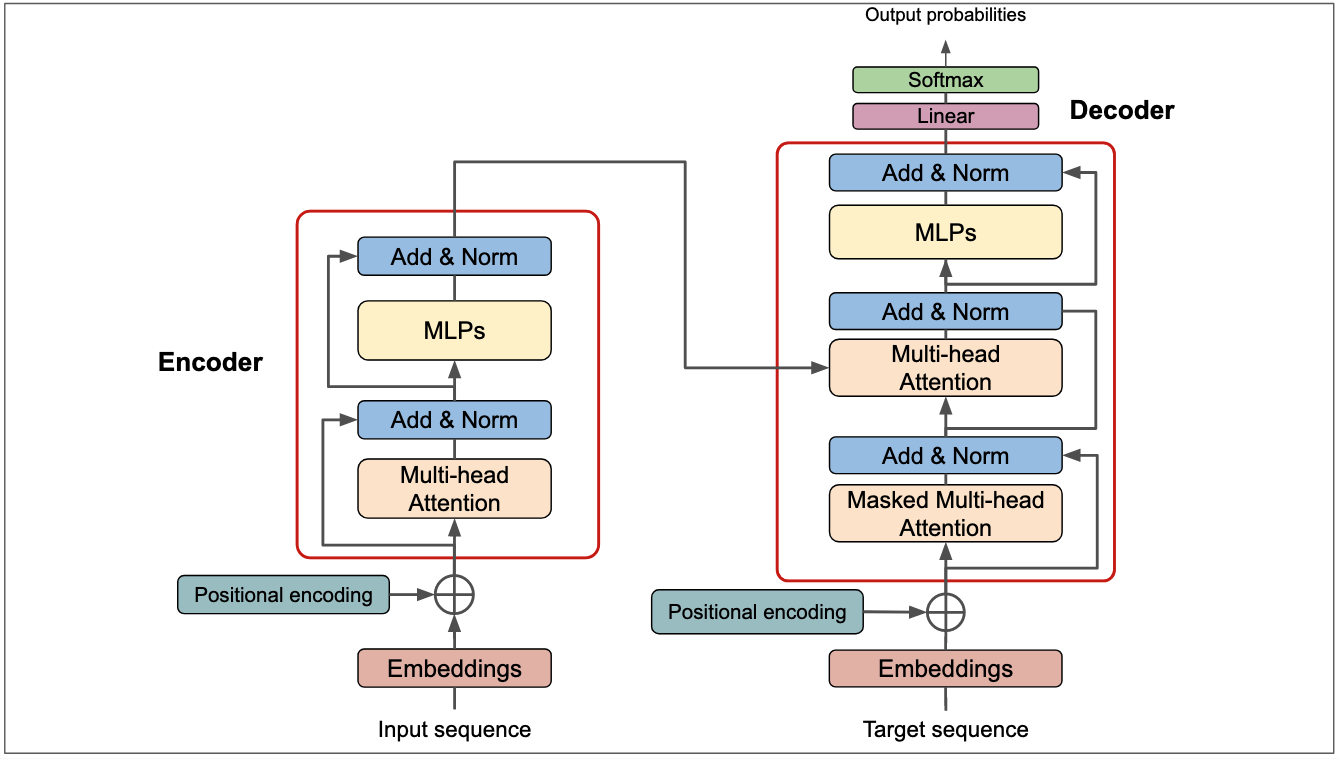
1.2 Contextual Modeling and Semantic Understanding (Transformer Backbone)#
| Component |
Description |
Problem Solved |
| Multi-layer Transformer Encoder |
Multi-head self-attention mechanism to encode context |
Understand long-range dependencies, capture syntax and semantics |
| Feed-Forward Network (FFN) |
Enhances non-linear representation ability |
Improves diversity and depth of model representations |
| Residual Connection & LayerNorm |
Stabilizes training, alleviates gradient vanishing |
Improves trainability of deep networks |
 |
|
|
1.3 Output Decoding / Generation#
| Component |
Description |
Problem Solved |
| Linear Projection + Softmax |
Maps the Transformer output to a probability distribution over the vocabulary |
Enables prediction and generation of the next token |
| Greedy / Beam / Sampling Decoding |
Strategies to select the next word/token from the probability distribution |
Controls the quality, diversity, and coherence of generated text |
LLM Solution from simple to complect#